Why I built it: Make Resume
Introduction
Long ago, when I was just getting started in my career, I realised I needed a means to distinguish myself from the other recent graduates and show off my abilities before I even got to the interview stage.
To do this, I set out to create a resume that would stand out from the crowd by departing from the default Microsoft Word format. Initially, I used Photoshop to accomplish this, but it was really unpleasant and had alignment problems. The resume had a decent appearance, but when it was exported as a PDF, it wasn't very compatible and became a large file that required several compression steps.
I started playing around with Vue.js at this time, which I would go on to use for most of my ongoing career. While experiencing the joy of component based development which I had briefly touched on with Angular 1.x I realised that I could create a much better resume using the browsers ability to print a webpage to a PDF.
Initial implementations of this concept were rather ugly, with formatting that varied greatly based on the page's content. Before choosing a hand-rolled technique that would determine page breaks on print and provide padding as best it could, I would research options like PDF.js while striving to improve upon the current pitfalls.
After a tonne of testing and debugging, I finally had the first iteration of MakeResu.me! This was simply a repository where you would enter a few configuration options before starting a webserver to print the displayed page.
I have no idea why I was such a fan of this red color at the time.
Building the resume service
I realised I could productise this once I had a repository that could generate a resume from a configuration by creating a web service that would automatically complete the configuration and generate the resume, removing any friction that would result from having to do it manually.
At the time, I was also straying from my usual DigitalOcean/AWS architecture and experimenting more with CI/CD and PaaS providers like Heroku. I chose to build and launch my service on Heroku with Travis as the deployment tool in order to learn more about the aforementioned service providers.
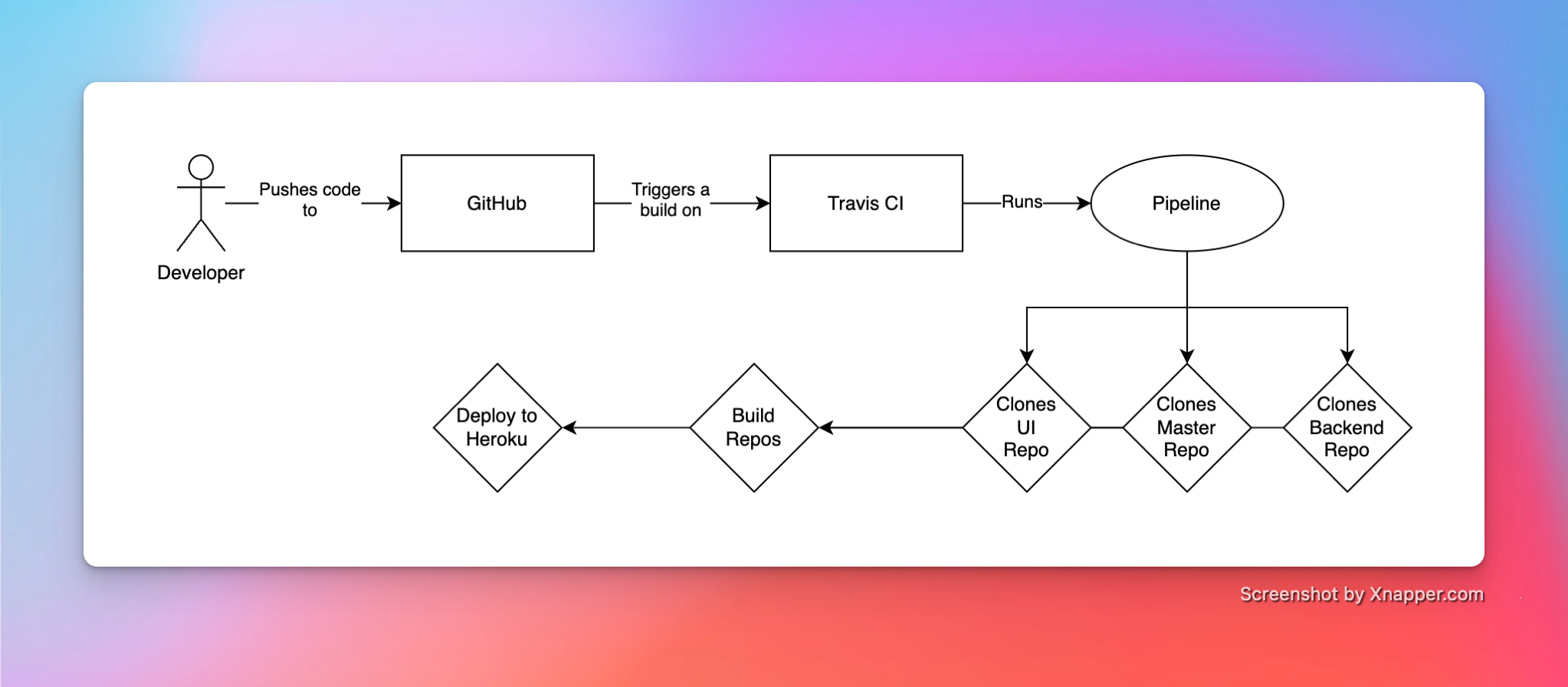
In retrospect, this first iteration of the service was a mess because I didn't know about monorepos and instead had three separate repositories for the UI, Backend, and Resume Template.
This was obviously a bad idea as it required some creative use of Travis and Github with a commit to a sub-repository creating a commit in the parent repository. This meant each repository needed to be aware of the others and trigger the appropriate builds on push to any of the above.
The pain that is printing webpages
When we print a webpage, the browser will make an effort to format the page as best as it can by moving text and other elements to other pages where they no longer fit while keeping page margins in mind.
For our resume, we wanted to handle most of the formatting and reflowing ourselves rather than making the browser work hard.
In order to achieve this, I first included a massive amount of CSS that would try to prevent page breaks along with some javascript that would run anytime a print command was made to check to see if an item was in a cut off point and then add padding to it as necessary.
To put things in perspective, Chrome will reformat a page to fit a 96ppi A4 page. An A4 page will be 794 pixels wide and 1123 pixels tall at 96ppi; I say approximately because the exact dimensions may vary slightly depending on the user's device pixel ratio.
Because of these inconsistencies, I can't rely on the user's device to generate a suitable PDF because it may differ from device to device. In addition, other browsers have various Webpage-to-PDF mechanisms that each have their own oddities.
To combat this the service would use Puppeteer to orchestrate a headless chromium instance to capture a PDF of the resume webpage.
These techniques mostly worked but would still encounter some issues which were typically handled by changing up the content and trying again. Unfortunately, the service wasn't really designed for retries and thus most users would simply give up after receiving a less than satisfactory result.
The death of Heroku and rebuilding of Make Resume
The service was launched and promoted on LinkedIn, however it remained largely dormant for years. While some resumes might break, it had served its purpose and did not require any immediate upgrades. At the time, I lacked the skills and desire to fix it.
From 2018 till 2022, the resume service remained in its current form, with an update in 2020 to handle new lines in descriptions so we could give our paragraphs a little breathing room.
Our dynos would be updated in the background with fixes pushed as needed, thus this absence of updates posed no harm to the service, which is largely thanks to Heroku.
Heroku, however, was acquired by Salesforce and in 2022 experienced a number of problems with price and security. Although I continued to monitor Heroku, I no longer used it for any new projects and instead relied on services such as Vercel and Firebase.
As a result of these problems and adjustments, as well as the fact that my previous domain had expired and had been squatted for the duration of the registration grace period by an unidentified entity, I made the decision to rebuild the service and make some changes to the user interface.
The new architecture
Instead of Vue 2 and hand-rolled CSS, I would use Vue 3 and Tailwind this time. Firebase would be used to host functions and create anonymous users so that past resumes could be stored with Firestore acting as a backend database.
The frontend would be hosted by Vercel so I could make use of a global CDN and incredibly quick builds.
Additionally, I would strengthen our page-break handler by updating it to calculate when a particular element would exceed a page and then prepend the exceeding element with an invisible element that would push it to the next page.
const PAGE_HEIGHT = 1123;
document.addEventListener("onprint", () => {
const breakables = document.querySelectorAll<HTMLElement>(".breakable");
breakables.forEach((breakable) => {
const { top, height } = breakable.getBoundingClientRect();
const remainder = top % PAGE_HEIGHT;
if (remainder + height > PAGE_HEIGHT) {
const exceededBy = PAGE_HEIGHT - remainder;
const spacer = document.createElement("div");
spacer.style.height = `${exceededBy}px`;
breakable.parentNode?.insertBefore(spacer, breakable);
breakable.classList.add("pt-12");
breakable.style.marginTop = "0px";
}
});
});The future of Make Resume
While the Firebase experience was pleasant, I've been yearning for more. Sadly, Google Cloud has the slowest cold-start time out of any of the major cloud providers. Using the Make Resume service, where some queries can take up to 30 seconds to finish upon hitting a cold start clearly highlights this slowness.
Additionally, it takes a very long time to deploy Firebase Functions; with the command firebase deploy --only functions it takes my current minimal build about 5 minutes to deploy. For context, I only have 3 functions for the Make Resume service, so this seems excessively long.
For quicker cold-start times and simpler deployments in the future, I'll likely switch to Vercel Functions and Browserless.io.
My crazy vision has always been to utilise Make Resume to store resumes and match them with openings at reputable companies. Although it hasn't happened yet, maybe someday when I'm more motivated and have more time on my hands, I'll work on a parser for SEEK or something comparable that can extract job phrases and perform fuzzy matches between users who have chosen to receive job notifications or something similar.
For now, I'll be content with what I've created thus far and come back later when I start to feel the resume and job matching itch once more.
